
OpenAIから発表されたSoraは最長1分間の高品質な動画を生成できる動画生成AIです。
クオリティが高すぎるため、いったいどういう仕組みで生成しているのか非常に気になりますよね。
また、APIを使って外部ツールと連携することはできるのでしょうか。
この記事は、Soraの仕組みやAPIの利用方法について解説していきます。
OpenAI「Sora」とは?できることや使い方
Soraは「Text-To-Video」モデルの動画生成AIサービスです。
「Text-To-Video」というのは、テキストで入力したプロンプトを基に動画を生成してくれるモデルですが、Soraはテキスト以外にも、画像から動画を生成したり既存の動画を拡張・編集したりといった機能も備えています。
最長1分間の動画生成が可能で、生成される動画も非常に高品質なものになっています。
Soraの使い方や動画生成方法、どんな動画が生成できるのかについては別の記事でまとめていますのでそちらをご覧ください。

OpenAI「Sora」が動画生成する仕組みを技術構成から解説
Soraの技術的な詳細はOpenAIからテクニカルレポートが発表されています。
まず一番重要なポイントはSoraの生成モデルが「Diffusion Transformer(Transformerアーキテクチャを用いた拡散モデル)」であるという点です。
Sora is a diffusion transformer.
引用元:OpenAI
そのためSoraは動画生成AIではありますが、画像生成AIと同じように元の画像に膨大な量のノイズを加え、今度はノイズを除去していくという作業の中で学習をしていきます。
具体的には以下の3つの技術要素で構成されています。
- 動画データを時空潜在パッチへ変換
- Diffusion Transformerによる動画生成
- DALL-E3のキャプショニングを応用
それぞれ解説します。
動画データを時空潜在パッチへ変換
まず動画データを「低次元の潜在空間」に圧縮をします。

このプロセスによりデータ量を削減し、Diffusion Transformerで学習する際の学習効率を高めます。
画像生成でいうところのVAEに相当する部分と思って相違ないでしょう。
Soraの場合は、圧縮された「低次元の潜在空間」をさらに「時空潜在パッチへ」分解することでパッチ化します。
これはLLMでいうところのテキストトークンに相当する部分です。
Diffusion Transformerによる動画生成
次に先ほどのデータを「Diffusion Transformer(Transformerアーキテクチャを用いた拡散モデル)」というAIモデルで処理します。
時空潜在パッチにノイズをかけ、Diffusion Transformerで一気に学習することで、まるで画像を生成するように動画を生成できます。

従来の「Diffusion Model(拡散モデル)」では、しばしば「U-Net(セマンティックセグメンテーション用モデル)」がアーキテクチャとして採用されており、これは特に画像生成タスクにおいて効果的です。
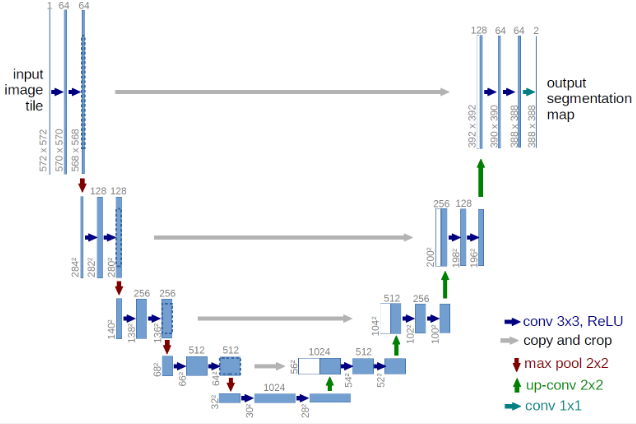
一方、Diffusion TransformerはDiffusion ModelのアプローチにTransformerアーキテクチャを組み込んだもので、これによりモデルはより複雑なデータの生成が可能になります。
DALL-E3のキャプショニングを応用
DALL-E3のキャプショニングが優れているため、Soraではこの技術が応用されています。
Text-To-Video生成システムのトレーニングには、対応するテキスト・キャプションを持つ大量のビデオが必要である。我々は、DALL-E3で導入されたリキャプション技術を動画に適用する。まず、高度に記述的なキャプションモデルを学習し、そのモデルを用いて、学習セットのすべての動画に対してテキストキャプションを生成する。記述性の高い動画キャプションを学習することで、動画の全体的な品質だけでなく、テキストの忠実度も向上することが分かる。
引用元:OpenAI
キャプショニングとは、画像やビデオの内容に対して適切な説明文を生成するプロセスのことを指します。
DALL-E3のキャプショニングを応用することで、ユーザーが入力した短いプロンプトを長い詳細なキャプションに変換してSoraに送信できます。
そのため、ユーザーの入力したプロンプトに従った高品質な動画生成ができるわけです。
OpenAI「Sora」の技術的課題からできないことや問題点
Soraは今までにないレベルで高品質な動画を生成してくれます。
しかし、まだまだ技術的な課題からできないことがあります。
物理法則や因果関係への理解
OpenAIは、現実世界の物理法則や物事の因果関係に対する理解がまだ乏しいと言っています。
ほかにも、時間経過による変化の表現も苦手なようです。
現在のモデルには弱点がある。複雑なシーンの物理を正確にシミュレートすることに苦労するかもしれないし、原因と結果の具体的な例を理解できないかもしれない。例えば、人はクッキーをかじるかもしれないが、その後、クッキーにはかじった跡がないかもしれない。
また、プロンプトの空間的な詳細、たとえば左と右を混同したり、特定のカメラの軌跡をたどるような、時間をかけて起こる出来事の正確な描写に苦戦することもある。
引用元:OpenAI
以下は例として発表されているコップが割れる映像です。
ガラスが割れて飲み物がこぼれるという現象に対して、物理法則を理解できていないのが分かります。
ほかにもランニングマシンを逆向きに走る映像もあります。
このようにSoraは物理法則や因果関係(原因と結果)を理解しきれていないというのが現時点の弱点と言われています。
フェイク動画や悪意あるコンテンツが出回る危険性
Soraの生成する動画は本当に撮影された映像と区別がつかないほど高品質です。
そのため、このまま一般公開した場合、世の中はフェイク動画で溢れかえるでしょう。
現在OpenAIではレッドチーム(AIの安全性や倫理性を評価する専門チーム)と共にいくつかの安全対策を講じるとしています。
例えばSoraで生成した動画と分かるようにメタデータを含める予定だそうです。
動画がSoraによって生成されたかを判別する検出分類器など、誤解を招くコンテンツの検出に役立つツールも構築しています。将来、OpenAI製品にこのモデルを導入する際には、C2PAのメタデータを含める予定です。
引用元:OpenAI
また、ほかにも暴力的なコンテンツや性的なコンテンツなど、ポリシー違反となるプロンプトは拒否するとも言っています。
過激な暴力、性的コンテンツ、嫌がらせ的な画像、有名人の肖像、または他人のIPを要求するような、使用ポリシーに違反するテキスト入力プロンプトをチェックし、拒否します。
引用元:OpenAI
しかし生成AIに関してはさまざまな法規制が追い付いていないことが実情です。
正式リリースされたのち、どういった影響があるのかはまだ不透明といえるでしょう。
OpenAI「Sora」のAPIについて!公開状況や利用方法
ChatGPTが登場した際にも、さまざまな外部ツールがAPI連携することで、より便利になりました。
開発者や技術者の方々なら、SoraのAPIが公開されるのかは、非常に気になる点だと思います。
しかし、残念ながら記事執筆時点ではまだAPIに関する情報は出てきていません。
OpenAIのフォーラムでも質問が上がっていますが、具体的な回答は得られていません。
APIの情報に関してはわかり次第、記事にしていく予定です。
まとめ:OpenAI「Sora」とは?動画生成の仕組みやAPIの利用方法など技術解説
- SoraはDiffusion Transformerモデルである
- Soraは物理法則や因果関係への理解が苦手
- SoraのAPIはまだ公開されていない
コメント